




Exploring Snowpark and Streamlit for Data Science
Industry Leader, Financial Services and Consumer, EMEA
Let's start engineering impact together
GlobalLogic provides unique experience and expertise at the intersection of data, design, and engineering.
Get in touchThroughout this blog, I aim to shed light on the remarkable potential that emerges when we use Snowpark and Streamlit together for solutions in Data Science. I will explore the seamless integration of these two technologies and demonstrate how they can be effectively utilised.
By sharing practical examples of using these technologies, I will show how Snowpark and Streamlit enable the creation of proof-of-concepts and provide valuable solutions without relying on traditional cloud providers like AWS, GCP, or Azure.
First things first:
What is Snowpark?
Snowpark is a new feature in Snowflake, a cloud-based data warehousing platform. It allows developers to write complex data transformations, analytics, and machine learning models using familiar programming languages like Java, Scala, and Python. This allows for complex data processing and analysis to be performed directly within Snowflake, without the need to move data between different systems or languages.
What is Streamlit?
Streamlit is an open-source framework that simplifies the process of creating web applications. As it is built on top of Python, users can easily leverage the multiple pre-built components Streamlit offers – including text inputs, buttons, and sliders. Additionally, users can use data visualisation libraries – like Matplotlib and Plotly –to create interactive and dynamic graphs.
With this being the first time I used Snowpark, I wanted to explore this new technology and figure out where and how it would be used within the data science realm. The best way to find this out, was to use Snowpark and Streamlit first hand and see how easy or hard it will be to use.
The Demo:
I created a demo to provide first-hand insights into how easy or hard it may be to use Snowpark and Streamlit. This demo involved scraping tweets from a particular Twitter user and running sentiment analysis on the tweets to generate valuable insights into the user’s profile.
Using Streamlit, I presented the results in an interactive manner; displaying information such as the user’s sentiment trends and the topics they most frequently tweet about.
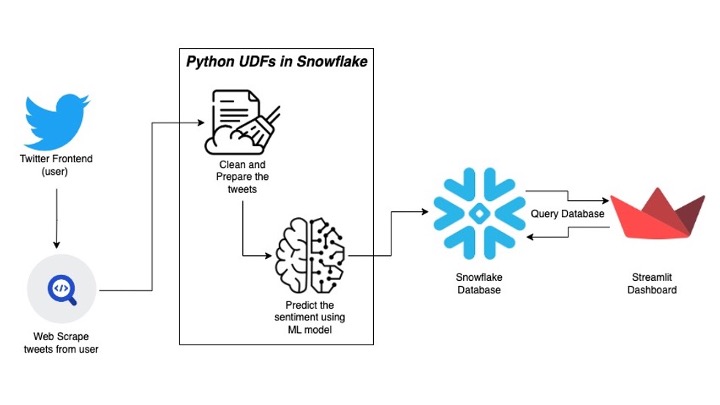
The process:
The first step was to find a tweet scraping tool that would allow me to retrieve a large number of tweets in a single query.
After some research, I decided to use SNScrape – a scraping tool for social networking services that can scrape user profiles, hashtags, and searches, and return discovered items like relevant posts.
To retrieve the tweets, it’s as simple as just a line of code – this line of code retrieves the tweets and inserts it into a json file.
snscrape –jsonl twitter-user {username} >twitter-@{username}.json
The next step was to clean and prepare the tweets. Once cleaned, these tweets were ready for analysis and helped improve the accuracy of the sentiment prediction model.
Cleaning the tweets included:
- Removing any irrelevant information (URLS, usernames and hashtags).
- Converting the text to lowercase and reducing the number of unique words.
- Removing special characters and punctuation marks.
- Removing stop words (for example: the, and, a, etc.)
- Tokenise the text – this is a common technique used in data cleaning to pre-process text data by breaking it down into smaller units called tokens, typically words or phrases.
This can all be done using a User Defined Function (UDF) – a custom function created by the user in Snowpark to perform complex computations or data transformations that are not natively available in Snowflake. UDFs are written in a supported programming language and are executed within a Snowpark session. They take input parameters and return values and can be reused across multiple sessions.
Using UDFs allowed me to shift processing power to Snowflake’s warehouses, saving my laptop from performing queries. Snowflake’s cloud-native architecture can execute UDFs and handle query execution and data processing efficiently.
Using UDFs is super easy – for example, you can create a simple UDF like so:
#######Define the function for the UDF
def multiply_by_three(input_int_py: int):
return input_int_py*3
#######Upload UDF to Snowflake
session.udf.register(
func = multiply_by_three
, return_type = IntegerType()
, input_types = [IntegerType()]
, is_permanent = True
, name = ‘SNOWPARK_MULTIPLY_INTEGER_BY_THREE’
, replace = True
, stage_location = ‘@TWITTER_DEMO’
)
In this way, it is easy to create functions that you can reused as many times as you like. In this example, I created user defined functions for cleaning the tweets and performed the techniques mentioned above to clean the text. I then used TextBlob to accelerate how quickly I could predict the sentiment of the text.
After cleaning and using Textblob on the tweets, the plan was to insert the data into the Snowflake tables. It was as easy as:
session = Session.builder.configs(<connection_parameters>).create()
temp_df = session.create_dataframe(<data>)
temp_df.write.mode(“overwrite”).save_as_table(<table_name>)
I stored the data in Snowflake tables to optimise the app’s performance. By doing so, if a user queries the same user multiple times, their data will already be stored, and only new tweets will be added to the table. This approach significantly improves the speed of the app as it eliminates the need to clean and predict the sentiment of all tweets repeatedly whenever the same user is queried.
Once the data had been inserted into Snowflake, we could now query from it to send the data to our frontend, which I used Streamlit to present.
Using Python, I was able to create webpage components, generate plots and graphs, and develop a dashboard directly from Snowflake.
Streamlit made the process straightforward, and since I had used Python before, the coding seemed very intuitive. It simplifies app development by allowing you to write apps in the same way you write plain Python scripts. For instance, if you wanted to display plain text, using st.write(‘hello world’) would immediately show the text on the app. This approach to app development makes it easy to build interactive applications without the need for extensive coding knowledge.
Cloud vs local:
I found Streamlit’s dynamic nature to be very useful. It automatically detected changes in my source code, enabling the app to instantly rerun and reflect any updates in real-time. This made the development process efficient, as I could quickly iterate on changes and instantly see the results without any lag time.
There are two ways this works: first is to run Streamlit locally, this takes your source code directly from local directory; and then there is Streamlit cloud, which allows you to connect your GitHub to the Streamlit cloud and every time there is a push to the repository, it will update the application very quickly.
Here is a quick view of the application that I was able to make with the data I inserted into Snowflake. You can see in the app that there are customisable input fields and the ability to generate dynamic visualisations such as pie charts, line plots, and even word clouds.
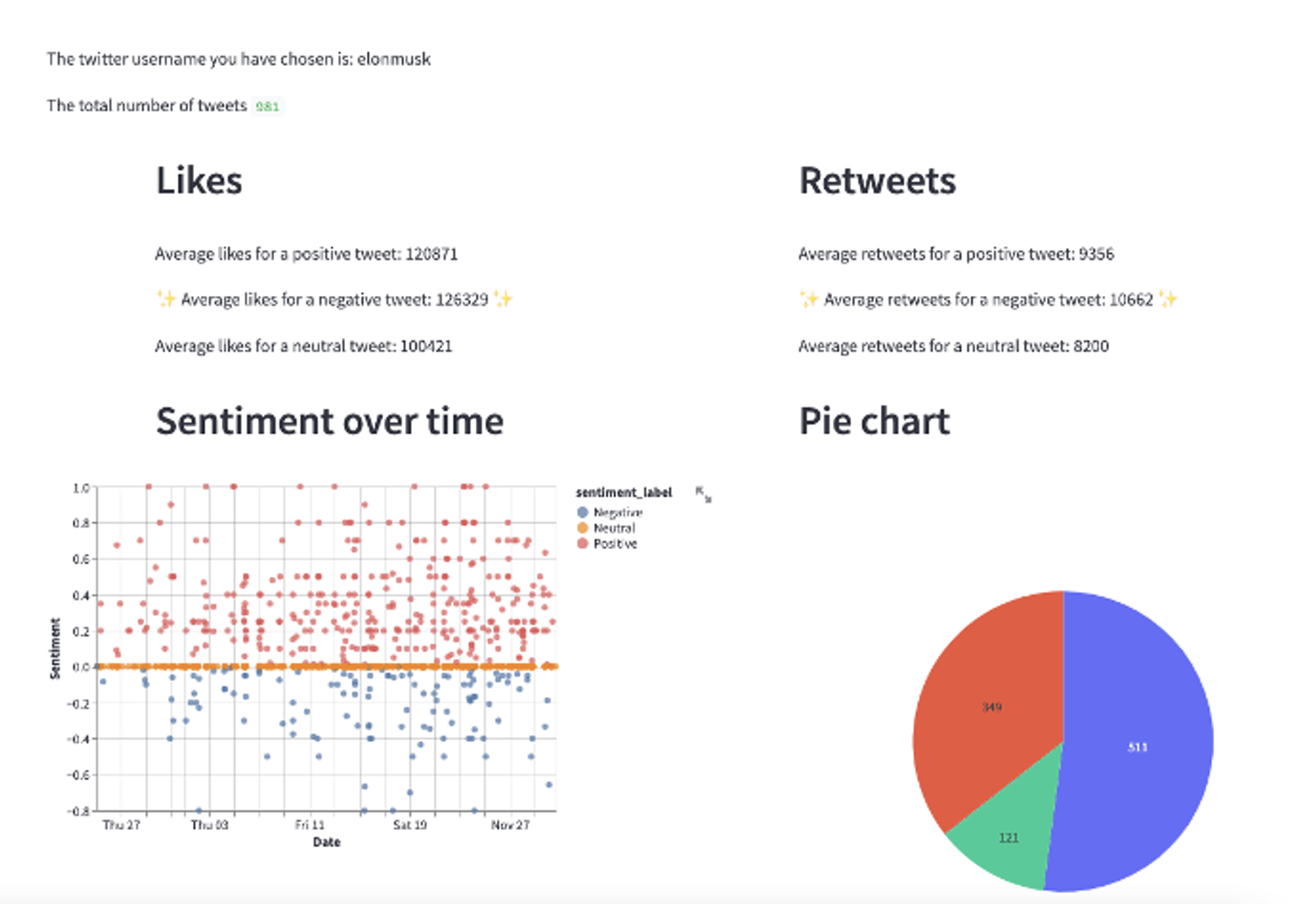
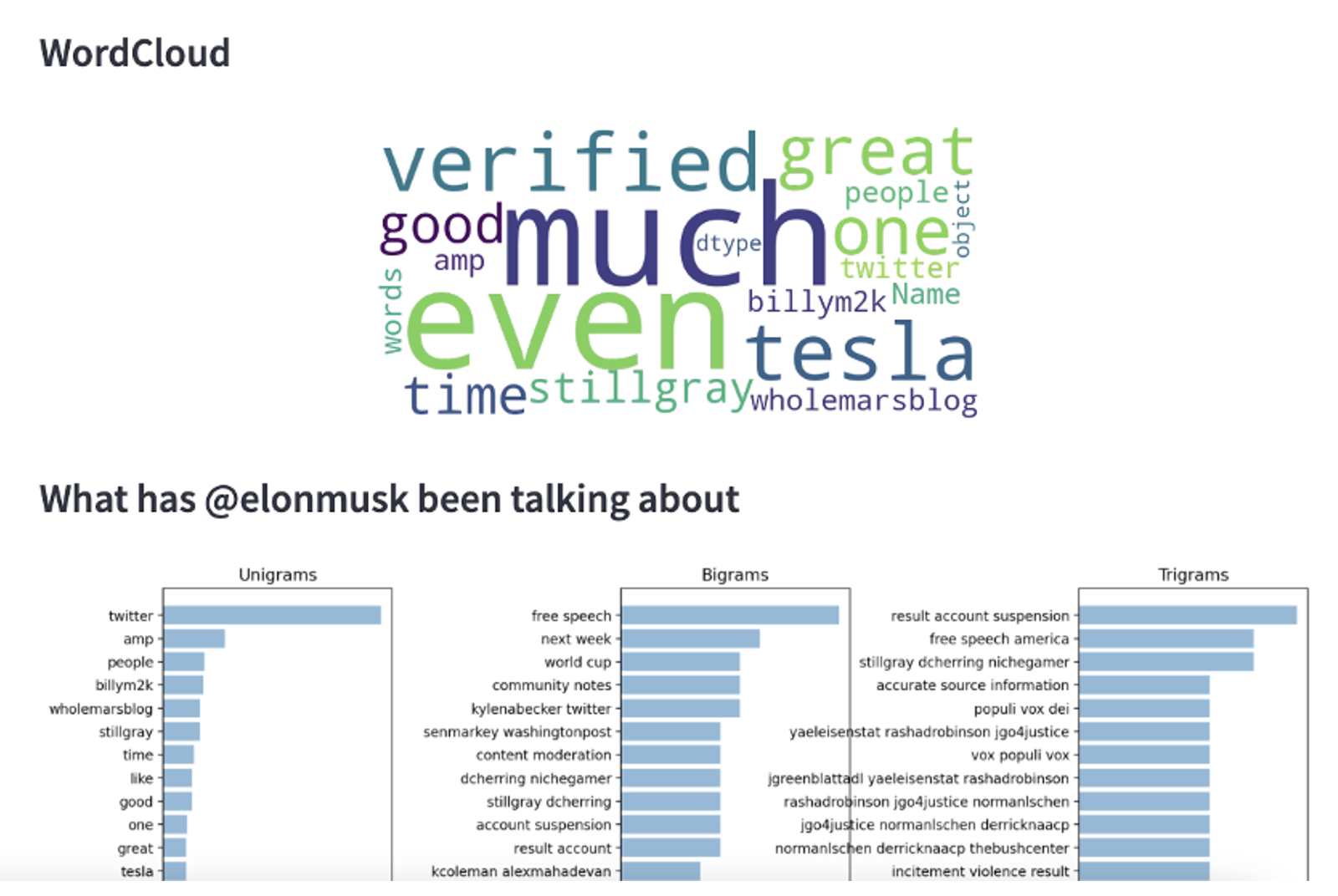
Lessons learnt:
Snowpark is still in its early stages of development, so there may be a limited ecosystem of libraries and resources available for developers to utilise.
When it came to using a UDF to predict the sentiment, I had tried to just use TextBlob to predict the sentiment, however this couldn’t be used within a UDF. Although the UDFs do support the use of third-party packages from Anaconda in a UDF – including Scikit-learn, Keras, TensorFlow, and other packages which can be useful for a Data Scientist.
Whilst working with Streamlit I found that even though it is a powerful tool for building data-driven applications, it may not be suitable for all use cases. Some users may require more advanced features or customisation options than Streamlit provides, which could limit its usefulness for these users.
For instance, it currently doesn’t integrate with Python Notebooks, which may be a drawback for some users. However, for creating simple proof-of-concept applications, Streamlit can be very effective and easy to use. It is important to consider your specific needs and requirements when deciding whether Streamlit is the right tool for your project.
My thoughts on these technologies:
My experience working with Snowpark and Streamlit was nothing short of impressive, particularly for a Data Scientist looking to create rapid demos to showcase their models.
I found the integration of the two platforms to be useful, as it allowed me to easily build and showcase data visualisations and models without requiring extensive development time.
While there may be some costs associated with using Snowpark or Snowflake, the performance gains and scalability benefits often outweigh these expenses. Similarly, while Streamlit may have some limitations in terms of functionality and flexibility, its ability to rapidly prototype data-driven applications makes it an invaluable tool for data scientists and developers alike.
Ultimately, the decision to use these technologies will depend on the specific needs and constraints of each project, but they are certainly worth considering as part of any modern data stack.
Our team here at GlobalLogic are highly experienced and love working all things Data Science and MLOps. If you are interested in working with us or just want to chat more about these topics in general, please feel free to contact Dr Sami Alsindi, Lead Data Scientist, at sami.alsindi@globallogic.com
More about the author:
Janki Makwana, a Data Scientist at GlobalLogic, has been a member of the GlobalLogic team in the UK&I region for two years now. She started as an associate consultant before proceeding to move to the Data Science Team. For the past year, Janki is working with a major retail and commercial bank as a subject matter expert in MLOps.