




MLOps Principles Part Two: Model Bias and Fairness

Industry Leader, Financial Services and Consumer, EMEA
Let's start engineering impact together
GlobalLogic provides unique experience and expertise at the intersection of data, design, and engineering.
Get in touchThis blog explores the various forms that model bias can take, whilst delving into the challenges of detecting and mitigating bias, and the ethical implications of using biased models.
Not only will we provide readers with a better understanding of the problem of model bias, we will introduce tools which can help to empower Data Scientists to make more informed decisions when developing and deploying machine learning models.
Model Bias
In recent years, the use of machine learning models has become increasingly prevalent in a wide range of applications. From self-driving cars to facial recognition technology, these models are being used to make important decisions that can have significant consequences on people’s lives.
However, one important issue that has come to light is the bias in these models. Model bias occurs when a model’s predictions are systematically skewed in favour of, or against, certain groups of people. This can lead to discriminatory and inaccurate decisions.
There have been several real-life examples of machine learning model bias affecting certain groups of people negatively. Here are just a couple of examples:
In 2018, it was revealed that Amazon’s AI-driven recruitment tool was biased against women. The algorithm was designed to analyse resumes and rank applicants based on their qualifications. However, since the training data consisted predominantly of male applicants’ resumes, the AI developed a preference for male applicants, disadvantaging women.
The Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) algorithm, used in the United States to predict the likelihood of re-offending, was shown to be biased against African Americans. A 2016 investigation by ProPublica found that the algorithm was more likely to falsely label African American defendants as high-risk, while white defendants were more likely to be labeled as low-risk, despite similar criminal records.
The examples above show that it is essential we appropriately address any potential model bias to reduce the risk of deploying unfair digital systems into society.
There are different types of model bias which we need to account for and they can originate in all the stages of our model development lifecycle.
Types of Model Bias
There are four different places in the machine learning lifecycle where bias can appear:
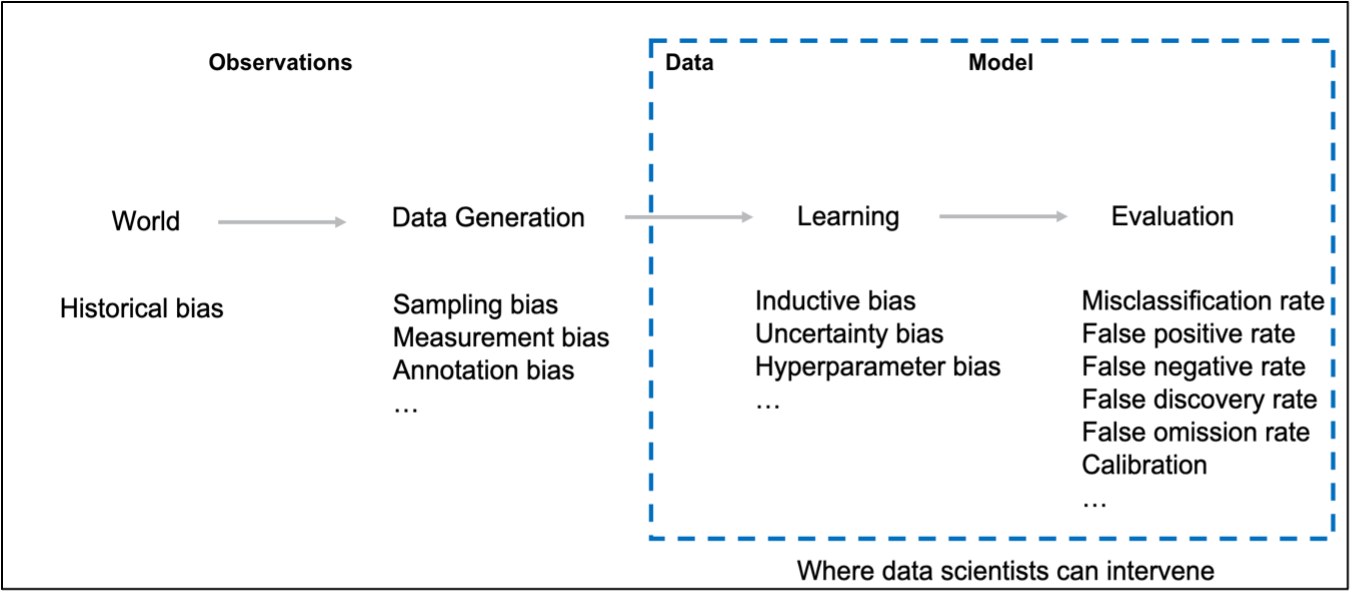
Figure 1 – Bias in the data science lifecycle
Bias originating from the world:
Bias originating from the world (also known as historical bias) can still occur with accurate data sampling. Even if the data represents the world perfectly, it can still inflict harm on a certain population – such as reinforcing a stereotype on a particular group.
Bias from data generation:
There are three main types of bias which can arise from the data generation stage of a data science lifecycle: sampling bias, measurement bias and annotation bias. Each bias essentially comes from what data is recorded from the real world into a useable format – for example, sampling bias often occurs when data has not been sampled correctly, which can cause underrepresentation of some part of a population and subsequently cause problems when used to generalise a whole population.
Bias from learning:
Learning bias exists if modelling choices amplify performance disparities across different examples in the data. For example, the objective function of an ML algorithm (e.g., cross-entropy loss for classification problems, or mean squared error for regression problems) that is used to optimise the model during training might unintentionally lead to a model with more false positives than desirable. Therefore, it is important to consider potential bias when making modelling choices and prioritise objectives (e.g., overall accuracy) in a way that does not damage another objective (e.g., disparate impact).
Bias from evaluation:
Evaluation bias can occur when the data which is being used to benchmark the model does not accurately represent the use population, therefore the metrics which are calculated in the testing phases of model production are not accurate to its performance in real life. This bias can further be exacerbated by the choice of metrics used to define model performance – for example, certain metrics such as accuracy could hide subgroup performance which may impact the prediction performance on a particular subgroup of the population.
Types of harms:
There are many different types of harms; below defines the most common types which can occur when using a ML system which inherently has some type of bias in it.
- Allocation harm: AI systems extend or withhold opportunities, resources, or information. Some of the key applications are in hiring, school admissions, and lending.
- Quality of service harm: System does not work as well for one person as it does for another – even if no opportunities, resources, or information are extended or withheld.
- Representative harm: When a system suggests completions which perpetuate stereotypes.
- Erasure harm: System behaves as if groups (or their works) do not exist.
Fairness Tree
As we have discussed, there are many different biases which can arise from several difference sources. Biases can be punitive (hurt individuals) or assistive (help individuals). To measure these different biases, we need to create several different metrics.
Data Scientists can use the Fairness Tree below as a guideline to pick the correct fairness metric to identify potential bias in their models. An example of each bias can be seen below in the corresponding fairness metric.
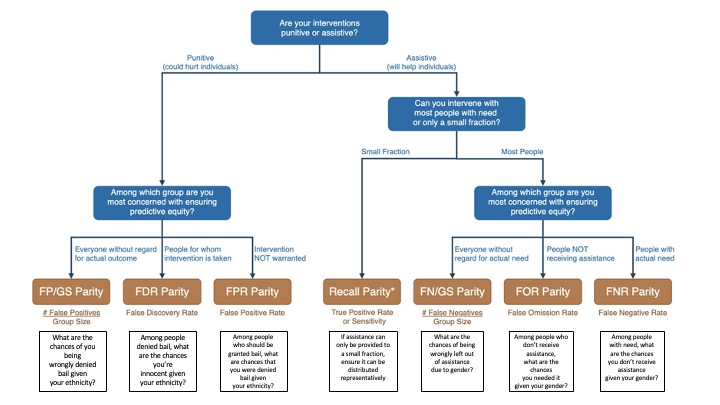
Figure 2 – Fairness Tree and examples of Bias
Image source: Aequitas
Tooling
There are several things we need to consider when picking a tool to help tackle bias and promote fairness. As we know, bias can arise in different parts of the data science process so we need to use a tool that can detect it in both the data and the model. We also saw from the Fairness Tree that there are many types of bias, all with their own metric to measure it. Ideally, we would need a tool which can compute all of these different metrics.
Aequitas (GitHub)
Originally Aequitas was developed by the Center for Data Science and Public Policy at the University of Chicago – it is an open-source Python toolkit for data scientists, ML researchers, and policy makers which can be used to create bias reports to audit data/models for any harmful bias or discrimination.
Aequitas allows the user to compute a suite of different metrics to measure the fairness of the data which will be used to train a ML model. The bias report uses four types of ‘fairness criteria’ to investigate if there is any bias towards protected groups within a model.
An example of this is shown in the snippet of a Bias Report below, taken from the Aequitas documentation:

A complete bias report can be found here.
AI Fairness 360 (GitHub)
Much like Aequitas, The AI Fairness 360 toolkit is a versatile open-source library that features methods created by researchers to identify and reduce bias in AI models during the entire AI application process (Figure 1). It can be used with both Python and R, and offers a complete suite of metrics for evaluating datasets and models for biases – alongside accompanying explanations and methods for reducing bias in datasets and models.
Conclusion
In conclusion, model bias is a complex and important issue that must be addressed in the development and deployment of ML models. While the field of machine learning has made significant progress in recent years, there is still much work to be done to ensure that these models are fair and accurate.
Detecting and mitigating bias requires a deep understanding of the data, the model, and the specific application for which it is being used. It also requires a commitment to transparency and ethical considerations.
As ML continues to shape the way we live and work, it is essential that we pay close attention to the issue of model bias. By staying informed about the latest research and best practices, we can work together to create more accurate, fair, and transparent models. Ultimately, this will lead to a better and fairer society for everyone.
Our team here at GlobalLogic UK&I are highly experienced and love working all things Data Science and MLOps. If you’re interested in working with us, or just want to chat more about these topics in general, feel free to contact Dr Sami Alsindi (Lead Data Scientist) at sami.alsindi@uk.globallogic.com.