





GlobalLogic, компанія групи Hitachi, – надійний партнер у сфері цифрового інжинірингу для найбільших і найсучасніших компаній світу.
Сьогодні ми допомагаємо трансформувати бізнеси та вдосконалювати індустрії через інтелектуальні продукти, платформи та послуги.
З 2000 року ми знаходимось на вістрі цифрової революції – допомагаємо створювати інноваційні та широковживані цифрові продукти і досвіди.
Дізнайтеся більше про те, що нас вирізняє0
інженерних центрів
0
+
активних клієнтів
0
+
фахівців у 26 країнах
0
+
релізів продуктів на рік
Що ми пропонуємо
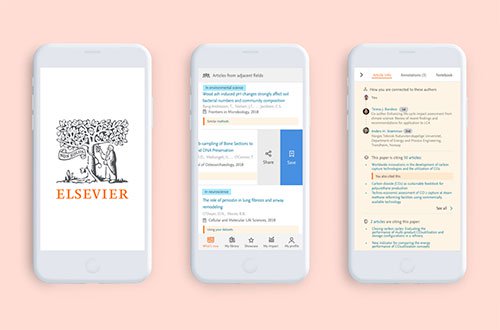
Відкрийте для себе розумні цифрові продукти, платформи та послуги в сфері охорони здоров’я.
Ми маємо глибокий вплив на повсякденне життя
Щодня мільярди людей взаємодіють з продуктами, платформами та послугами, які ми допомогли спроєктувати та реалізувати.
Наші кейс-стаді
Дізнайтеся, як ми створюємо вплив разом із клієнтами по всьому світу
Ознайомтеся з кейс-стаді


Зробіть
свій
внесок
Основні інсайти
Ознайомтеся з новими ідеями від стратегів та інженерів GlobalLogic
Дивитися всіBlogs

Blogs
Blogs
Зв’яжіться з нами
Створюйте інженерний вплив з нами
GlobalLogic надає унікальний досвід і експертизу на перетині даних, дизайну та інжинірингу.